Gedeeltelijke data aanlevering
Wanneer uw organisatie per batch data gaat aanleveren voor een registratie is het belangrijk dat de gegevens die u wilt aanleveren zijn vastgelegd in het informatiesysteem. In sommige gevallen is een deel van de benodigde data (nog) niet vastgelegd, bijvoorbeeld omdat de gegevens nog niet zijn uitgevraagd of niet worden vastgelegd in het informatie systeem. Het is ook mogelijk om slechts een gedeelte van de registratiegegevens aan te leveren via batch. De ontbrekende data kunt u dan op een later moment per batch aanleveren of handmatig invoeren met de applicatie DataEntry.
Voorwaarden gedeeltelijke batch-aanlevering
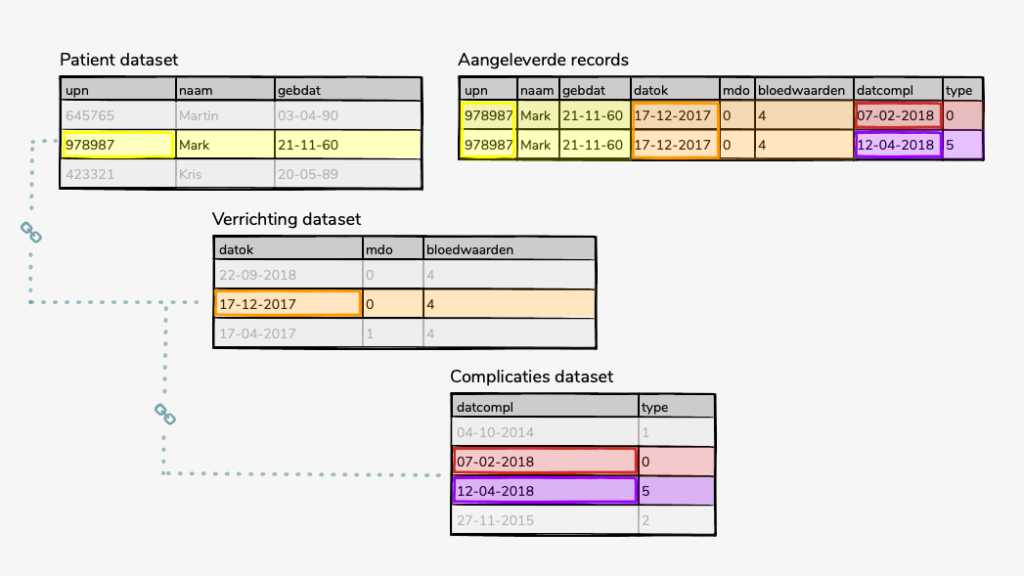
Er zijn een aantal voorwaarden verbonden aan een gedeeltelijke batch-aanlevering. Welke dat zijn leggen we uit aan de hand van een voorbeeld van een fictieve registratie. De fictieve registratie bestaat uit drie datasets: de patiënt-dataset, de verrichting-dataset en de complicatie-dataset. In de registratie schematisch weergegeven.
Registratie afhankelijkheden
Wanneer u een gedeelte van de data aanlevert dient u met een aantal aspecten van een registratie rekening te houden: de datasets, de dataset-keys en de relatie tussen de datasets.
De relatie tussen datasets
De drie datasets van de fictieve registratie zijn hiërarchisch met elkaar verbonden. De patiënt-dataset staat op het eerste en hoogste niveau in de registratie. De verrichting-dataset valt onder het patiënt-record, op het tweede niveau. De complicatie-dataset valt onder de verrichting-dataset en bevindt zich op het derde niveau in de registratie.
In onderstaand voorbeeld kunt u teruglezen hoe binnen een zogenaamde pre-fill aanlevering rekening wordt gehouden met de dataset-structuur van de registratie.
Voorbeeld:
U wilt alvast (een aantal) variabelen uit de verrichting-dataset aanleveren via een batch. De data uit de andere datasets vult u op een later moment via DataEntry of per batch aan. Hoe pakt u dit aan?
De verrichting-dataset hangt hiërarchisch onder de patient-dataset. Dit betekent dat bij het aanleveren van een verrichting-record ook het bijbehorende patient-record moet worden meegeleverd. Afhankelijk van het ingestelde aanleverscenario levert u het volledige patient-record aan of heeft u de mogelijkheid om alleen de dataset-key van het bijbehorende patient-record mee te leveren.
Afhankelijk van het ingestelde aanleverscenario kan per batch ook data aangevuld worden. In onderstaand voorbeeld kunt u teruglezen hoe u per batch een dataset-record uit een dieper niveau in de registratie kunt toevoegen
Voorbeeld:
U wilt een (aantal variabelen uit het) complicatie-record voor een patiënt aanleveren. Het bijbehorende patiënt- en verrichting-record zijn enige tijd geleden al aangeleverd via DataEntry. Hoe pakt u dit aan?
De complicatie dataset hangt hiërarchisch onder de verrichting-dataset. De verrichting dataset hangt hiërarchisch onder de patiënt-dataset. Dit betekent dat bij het aanleveren van het complicatie-record ook het bijbehorende patiënt-record en verrichting-record worden meegeleverd. Afhankelijk van het ingestelde aanleverscenario levert u het volledige patiënt- en verrichting-record aan of heeft u de mogelijkheid om alleen de dataset-keys van het verrichting- en patiënt-record mee te leveren.
Handmatig invoeren van data met DataEntry
Het is ook mogelijk om de ontbrekende gegevens handmatig via de applicatie DataEntry aan te vullen. Voor de meeste registraties kunt u via twee ingangen data registreren: via de webapplicatie DataEntry (invoerscherm) én via batch-aanlevering. Beide ingangen geven toegang tot dezelfde registratie. Gegevens die via batch zijn aangeleverd kunt u met DataEntry wijzigen, aanvullen en verwijderen. Let wel op, de laatst aangeleverd waarde wordt gezien als de waarheid. Het is dan ook belangrijk dat waarden welke bij ons in de database worden gewijzigd ook goed in het bronsysteem van uw zorginstelling staan.